
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- sklearn
- leetcode
- Tableau
- 데이터분석솔루션
- TensorFlow
- 데이터프레임
- python
- HackerRank
- 해커랭크
- 코랩
- 프로그래머스
- KNIME 데이터 분석
- Revising the Select Query II
- KNIME
- 리스트
- 물만날물고기
- pandas
- DB
- sorted()
- 태블로
- MYSQL
- 파이썬
- 물 만날 물고기
- 텐서플로우
- SQL
- colab
- pyinstaller
- 판다스
- 나임
- 코딩테스트
- Today
- Total
물 만날 물고기
[웹 크롤링] - Youtube playlist 재생목록 크롤링 + openpyxl로 제목에 하이퍼링크 연결하여 엑셀 파일로 추출하기 (feat. BANGTANTV-'Seven' playlist) 본문
[웹 크롤링] - Youtube playlist 재생목록 크롤링 + openpyxl로 제목에 하이퍼링크 연결하여 엑셀 파일로 추출하기 (feat. BANGTANTV-'Seven' playlist)
Lung Fish 2023. 7. 20. 23:10
🔍 예상 검색어
# 파이썬 웹 크롤링
# 유튜브 재생목록 크롤링
# openpyxl
# 엑셀 하이퍼링크 함수
# openpyxl 하이퍼링크 기능
# 유튜브 재생목록 파싱
# 유튜브 플레이리스트
# youtube playlist 파싱
# BANGTANTV-'Seven' playlist)
해당 포스팅은 유튜브 재생목록을 노션 또는 티스토리(블로그)에 복사-붙여넣기 위한 목적으로 BeautifulSoup을 이용하여 Youtube playlist를 크롤링하였고, openpyxl을 이용하여 제목에 url링크를 하이퍼링크로 연동한 결과를 엑셀 파일로 저장하는 코드를 정리한 포스팅입니다.
들어가며..
유튜브를 통해서 다양한 학습을 진행하고 있고, 아래와 같이 주제에 맞는 Playlist를 만들어서 학습하기 쉽도록 만들어주신 유튜버 분들이 많아서 정말 감사하게 생각하고 있습니다. 그런데 이제 학습을 진행하기 위해서 검색해서 찾아들어오는 것보다 영상 링크를 잘 간직하고 있다가 필요할 때 방문하면 더 편리할 것 같다는 생각을 하게 되었습니다.
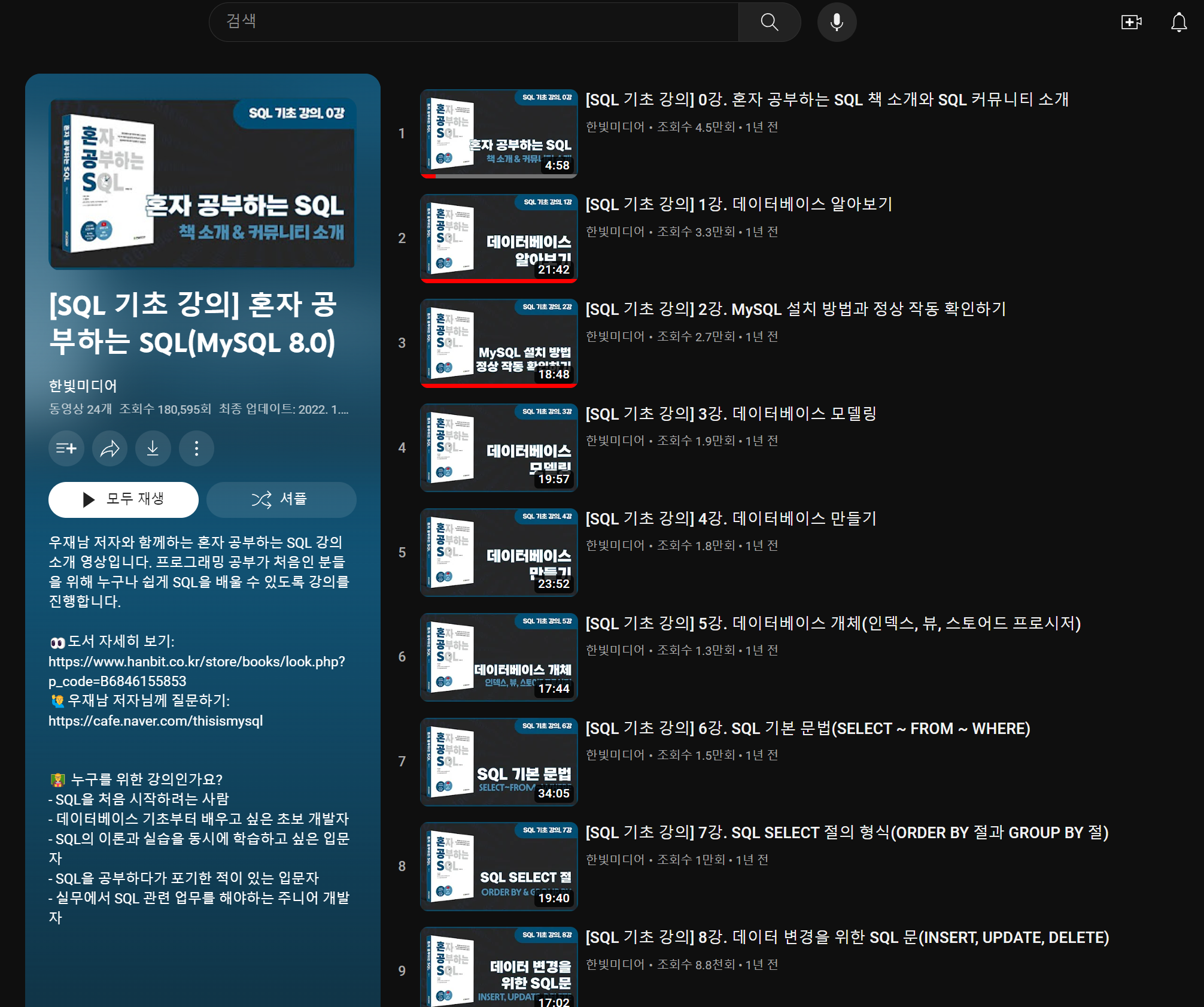
그래서 지금 보시는 것처럼 유튜브 재생목록을 파싱한 뒤, 이를 정리하여 아래와 같이 노션이나 메모 프로그램에 복사-붙여넣기 해놓고, 학습 진도를 체크하고 각 영상별로 학습내용을 정리할 때 활용하면 좋을 것 같다는 생각을 하게되었습니다.

위와 같이 유튜브 재생목록을 크롤링하는 방법과 해당 링크를 클릭하면 영상 주소로 이동될 수 있도록 엑셀파일로 추출하는 방법에 대해서 정리해보도록 하겠습니다.
🎈 실습 코드 및 예제 (BANGTANTV-'Seven' 의 Youtube playlist를 사용)
https://youtube.com/playlist?list=PL5hrGMysD_Gu7GSlCsT6unQqdcHL8rJ6S
💽 'Seven'
www.youtube.com
1. Youtube Playlist 주소 확인하기
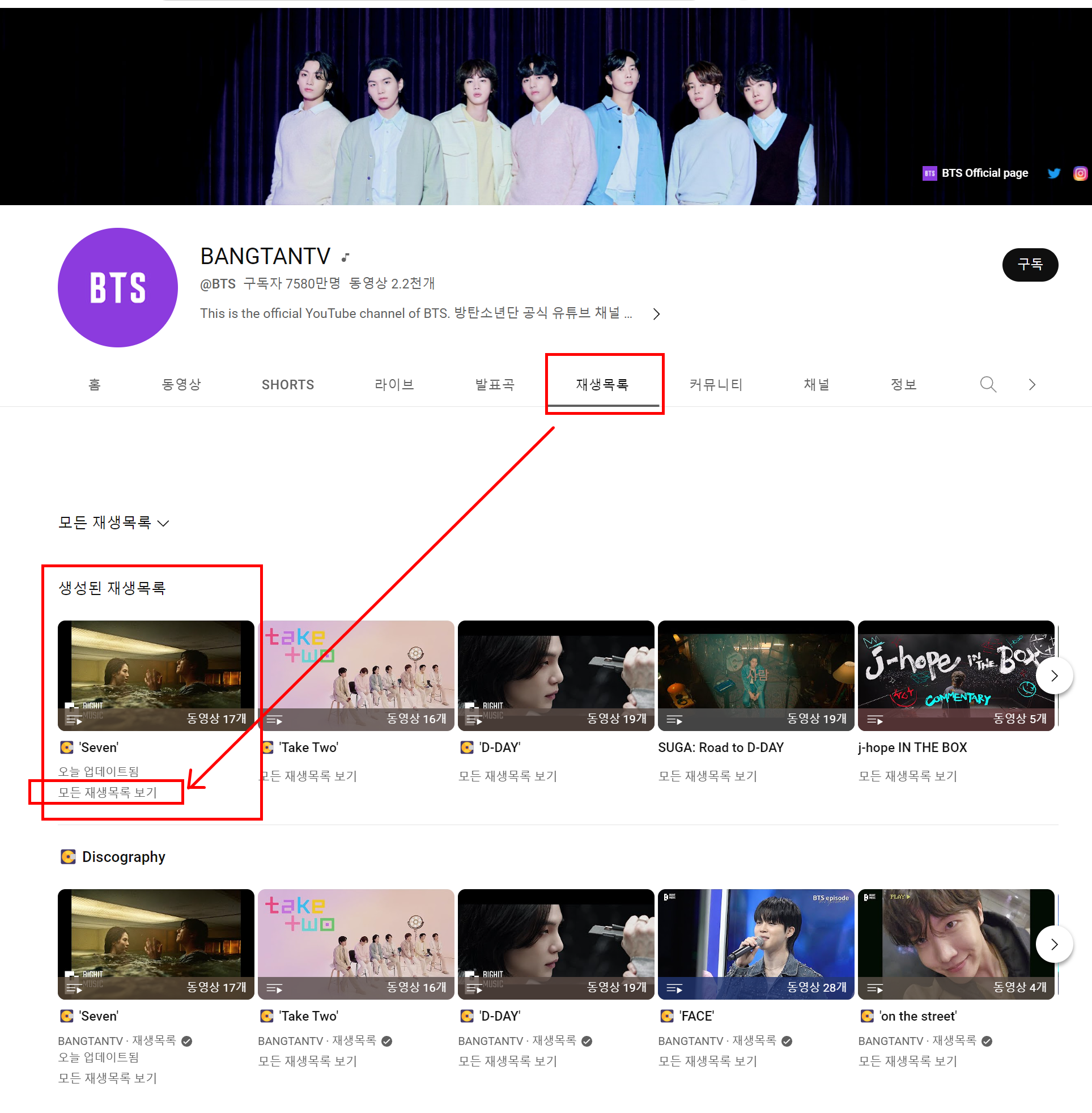
1.1 유튜브 구독자의 채널에 들어가면 "재생목록" 컨텐츠가 있습니다.
1.2 마음에 드는 재생목록에서 "모든 재생목록 보기"를 클릭하면 playlist를 확인할 수 있는 페이지로 이동합니다.
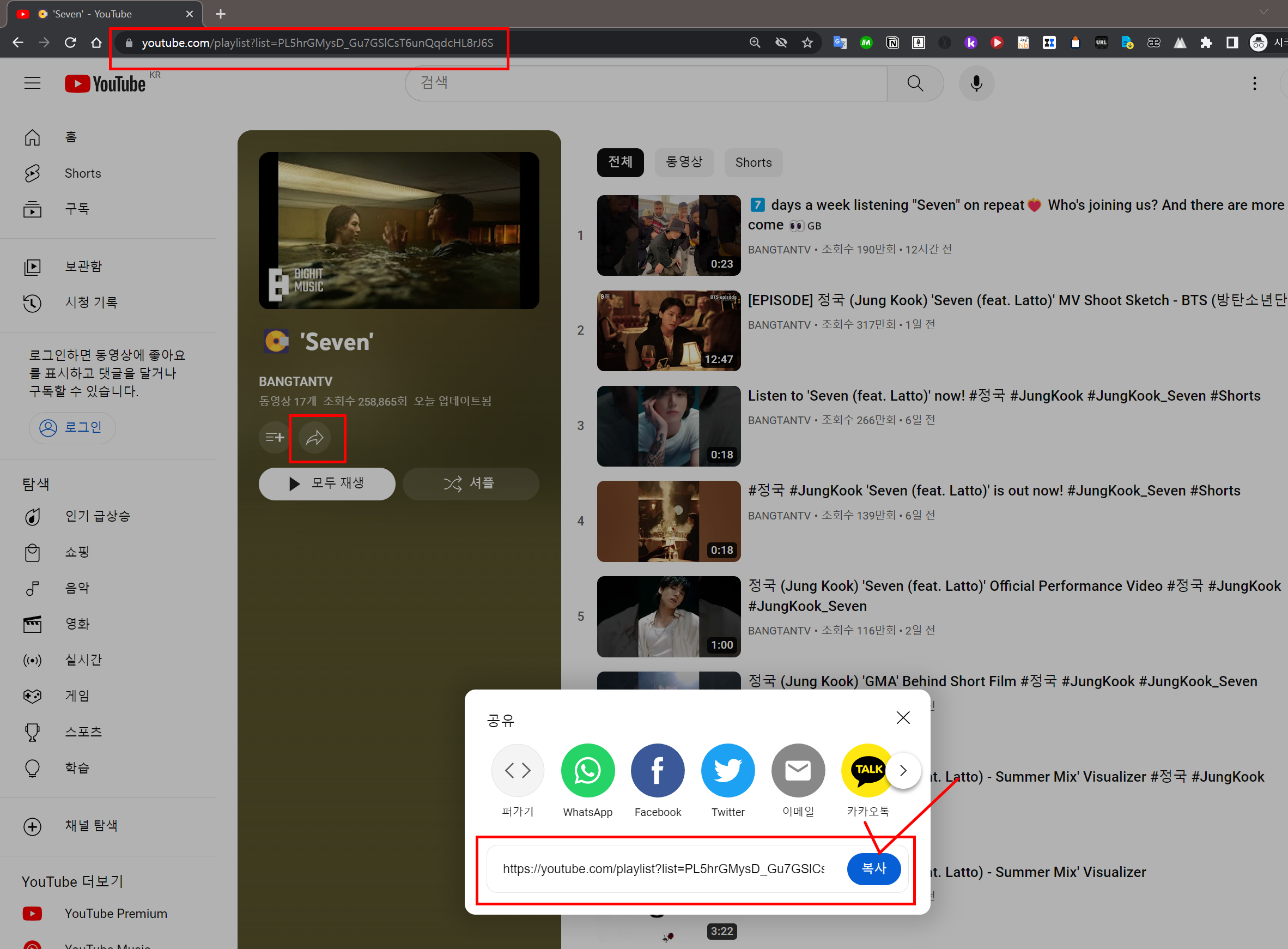
1.3 해당 페이지에서 url링크를 복사해도 괜찮고, "공유"버튼을 눌러서 url링크를 복사해도 괜찮습니다.
2. Youtube Playlist 스크래핑
2.1 위에서 복사한 Playlist의 url주소를 input으로 입력합니다.
# url 주소 입력
url = input('유튜브 재생목록 주소를 입력하세요: ')

2.2 웹 브러우저 작동을 위한 라이브러리를 import 해주고, playlist 페이지에 있는 영상의 제목, 재생시간, 영상링크를 파싱하고, 파싱 결과를 확인할 수 있도록 데이터프레임으로 출력합니다.
# 웹 브라우저 작동을 위한 라이브러리
from selenium import webdriver
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from selenium.webdriver.common.keys import Keys
# 웹브라우저 작동을 기다리기 위한 라이브러리
import time
import random
# 시간 관련 라이브러리
from datetime import datetime, timedelta
from pytz import timezone
# IPython
from IPython.display import display
# 경고 무시
import warnings
warnings.filterwarnings(action='ignore')
# 데이터프레임 및 CSV 파일 저장을 위한 라이브러리
import pandas as pd
# 데이터프레임 출력
from tabulate import tabulate
# 크롬드라이버 option설정
options = webdriver.ChromeOptions()
options.add_argument('--headless') # Head-less 설정
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
def get_playlist(url):
# 브라우저 생성
driver = webdriver.Chrome('chromedriver', options=options)
# 웹사이트 열기
driver.get(url)
# 로딩이 끝날 때까지 2초 정도 기다림
driver.implicitly_wait(2)
# 안정적인 페이지 소스 추출을 위해 3초 정도 기다림
time.sleep(3)
# 페이지 소스 추출
global html_source, soup_source
html_source = driver.page_source
soup_source = BeautifulSoup(html_source, 'lxml')
# 파싱정보 가져오기
parsing = soup_source.find_all('a', class_ = 'yt-simple-endpoint style-scope ytd-playlist-video-renderer')
video_time = soup_source.find_all('span', class_ ='style-scope ytd-thumbnail-overlay-time-status-renderer') #검색했을 때 검색숫자가 안맞아서 확인이 필요함
global name_list, url_list, time_list
# 파싱정보 정리하기
name_list = []
url_list = []
time_list = []
for i in range(len(parsing)):
name_list.append(parsing[i].text.strip())
main = 'https://www.youtube.com'
sub = parsing[i].get('href')
url_list.append(f'{main}{sub}')
time_list.append(video_time[i].text.strip())
# 출력용 데이터 프레임 구성하기
playlist = {
'제목' : name_list,
'시간' : time_list,
'URL' : url_list,
}
# 제목에서 제거할 문자 변환하기
playlist = pd.DataFrame(playlist)
return playlist
final_result = get_playlist(url)
final_result.index = final_result.index + 1
final_result
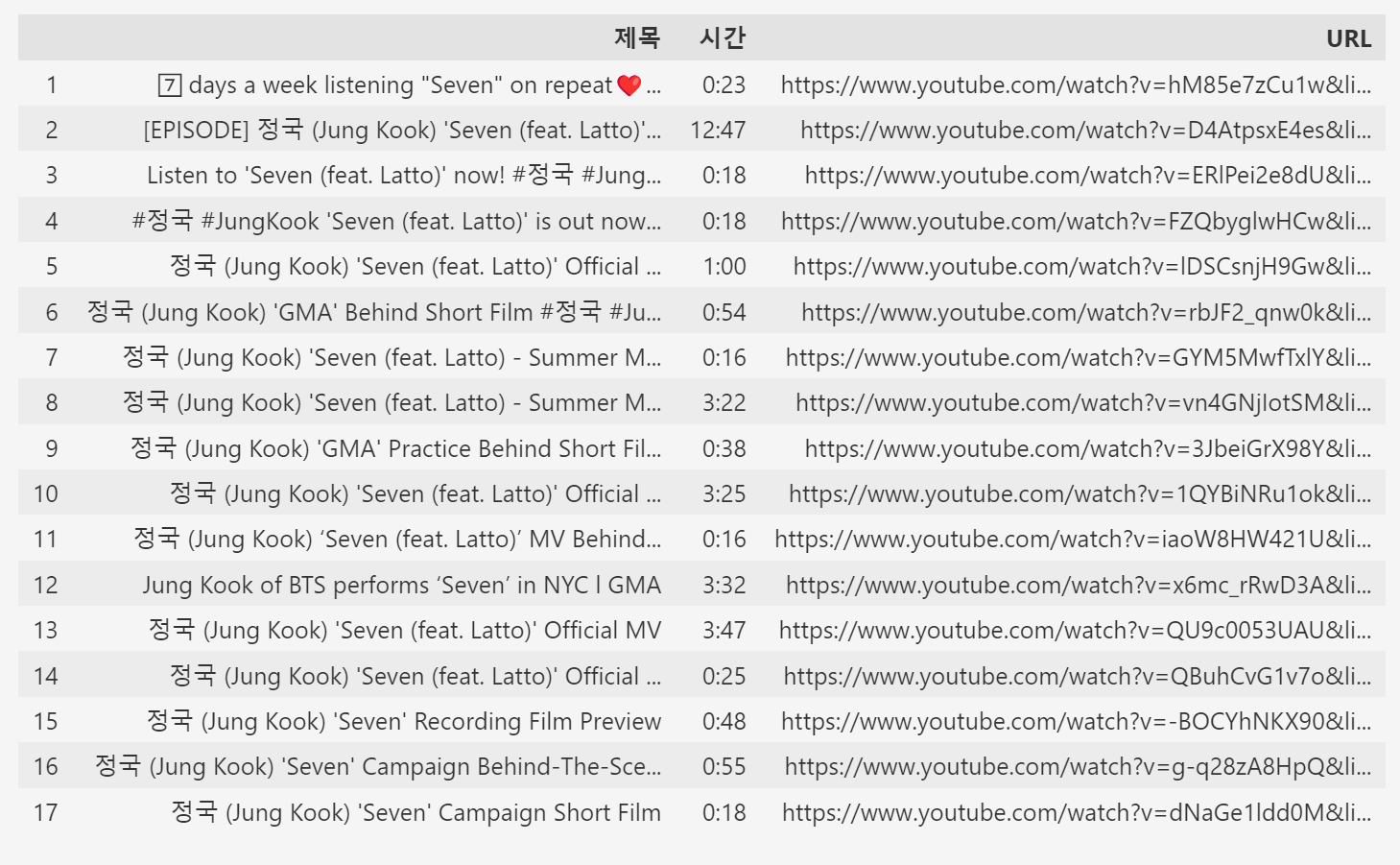
2.3 파싱결과를 확인합니다.
3. Youtube Playlist 스크래핑 결과를 openpyxl로 엑셀(xlsx)파일 저장하기
3.1 엑셀 파일로 저장하기 위한 openpyxl을 import 하고 파일과 워크시트를 생성합니다.
from openpyxl import Workbook
from openpyxl.styles import Border, Side
from openpyxl.utils import get_column_letter
from openpyxl.styles import Font
# URL and corresponding name lists
# Create a new workbook and worksheet
wb = Workbook()
ws = wb.active
3.2 엑셀 테두리에 사용할 스타일을 지정합니다.
# 테두리 스타일 지정
thin_border = Border(left=Side(style='thin'),
right=Side(style='thin'),
top=Side(style='thin'),
bottom=Side(style='thin'))
3.3 "유튜브 채널명" + "재생목록 이름" 으로 컬럼명을 만들어 줍니다. 앞에서 파싱한 결과를 이용하였습니다.
# 표 제목 (유튜브 채널명 + 재생목록 이름 으로 컬럼명 만들기)
list_title = soup_source.find(class_ = 'style-scope yt-dynamic-sizing-formatted-string yt-sans-28').text
channel_name = soup_source.find('a', class_ = 'yt-simple-endpoint style-scope yt-formatted-string').text
title = channel_name + "-" + list_title
# 제목셀과 재생시간셀 만들기
name_header_cell = ws.cell(row=1, column=1, value=title) # Insert name header into cell
name_header_cell.border = thin_border
name_header_cell.font = Font(bold=True)
time_header_cell = ws.cell(row=1, column=2, value="시간") # Insert URL header into cell
time_header_cell.border = thin_border
time_header_cell.font = Font(bold=True)
3.4 개별 동영상의 url 주소와 제목, 재생시간을 순서에 맞게 각 셀에 입력하고, hyperlink 기능을 이용하여 제목에 url링크가 반영될 수 있도록 해줍니다.

3.5 엑셀에서 HYPERLINK 함수는 (URL 주소 + 이름)으로 사용하는데, 아래처럼 URL주소와 재생리스트 제목을 결합하여 클릭하면 링크로 연결되도록 만들어 줄 수 있습니다. 이를 Python openpyxl에서도 사용해줄 수 있습니다.
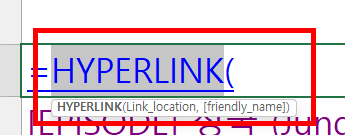
# Iterate through the URL and name lists, adding each URL to a new row
for url, name, time in zip(url_list, name_list, time_list):
row = ws.max_row + 1 # Next row number
name_cell = ws.cell(row=row, column=1, value=name) # Insert name into cell
name_cell.hyperlink = url # Add hyperlink to cell
name_cell.style = "Hyperlink" # Set cell style to "Hyperlink"
name_cell.border = thin_border # Add border to cell
time_cell = ws.cell(row=row, column=2, value=time) # Insert URL into cell
time_cell.border = thin_border # Add border to cell
3.6 셀 너비에 맞게 길이를 자동 조정 해주는 코드도 추가하였습니다.
# 셀의 너비를 셀의 내용에 맞게 자동 조정
for column in ws.columns:
max_length = 0
column = get_column_letter(column[0].column) # Get the column name
for cell in ws[column]: # Iterate through all cells in the column
try: # Check if the cell contains text
if len(str(cell.value)) > max_length:
max_length = len(cell.value)
except:
pass
adjusted_width = (max_length + 10)
ws.column_dimensions[column].width = adjusted_width
3.7 마지막으로 저장할 파일명을 입력 받고, 엑셀파일로 저장해주면 완성됩니다.
file_name = input("저장할 파일 이름을 입력하세요: ")
# Save changes and create Excel file
wb.save(f'{file_name}.xlsx')
4. 결과 확인
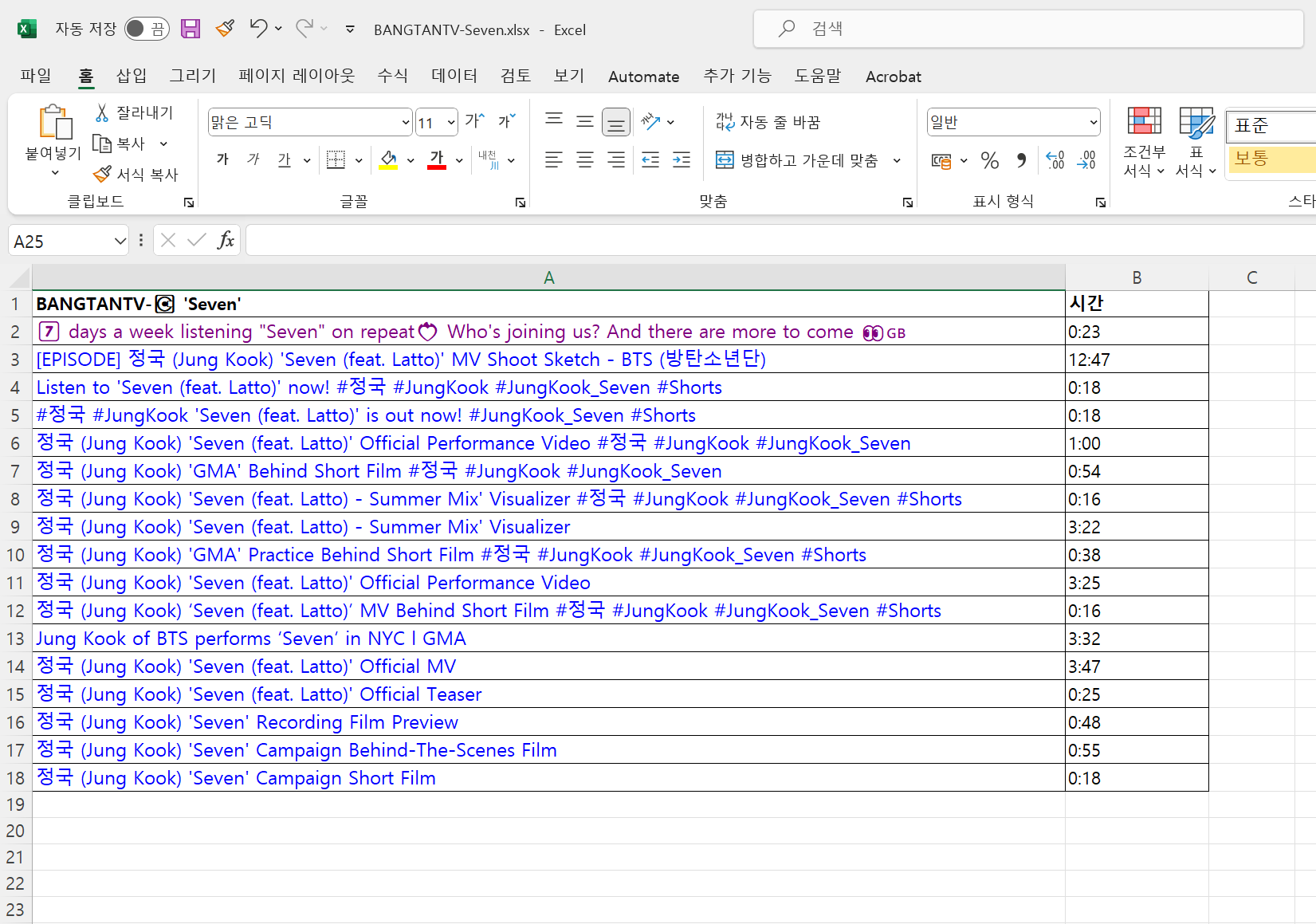
4.1 아래와 같이 BANGTANTV-Seven 재생목록이 엑셀파일로 추출되었습니다.

4.2 결과를 확인해보니 제목도 잘 반영되었고, 재생리스트에도 url이 반영되었고, 재생 시간도 잘 반영되었습니다.
5. 결과 활용하기 (노션, 티스토리)
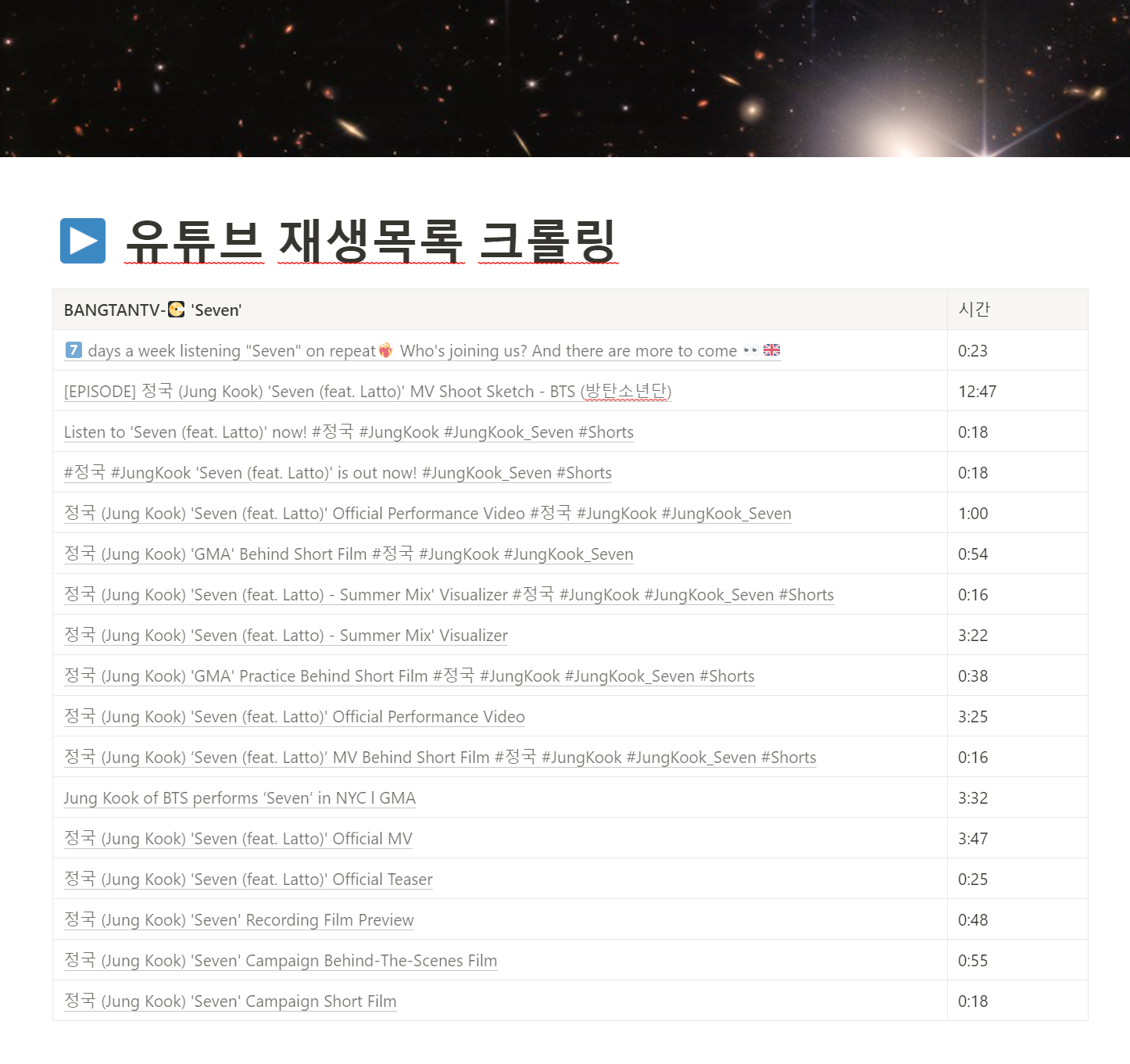
5.1 재생목록 리스트 엑셀 파일을 복사해서 노션에 붙여넣었더니, 재생목록 리스트가 깔끔하게 정리되었습니다.
5.2 노션에서 표 만들고 데이터 베이스로 만들고 싶으면 "옵션"에서 "제목 행"을 만들어주고,
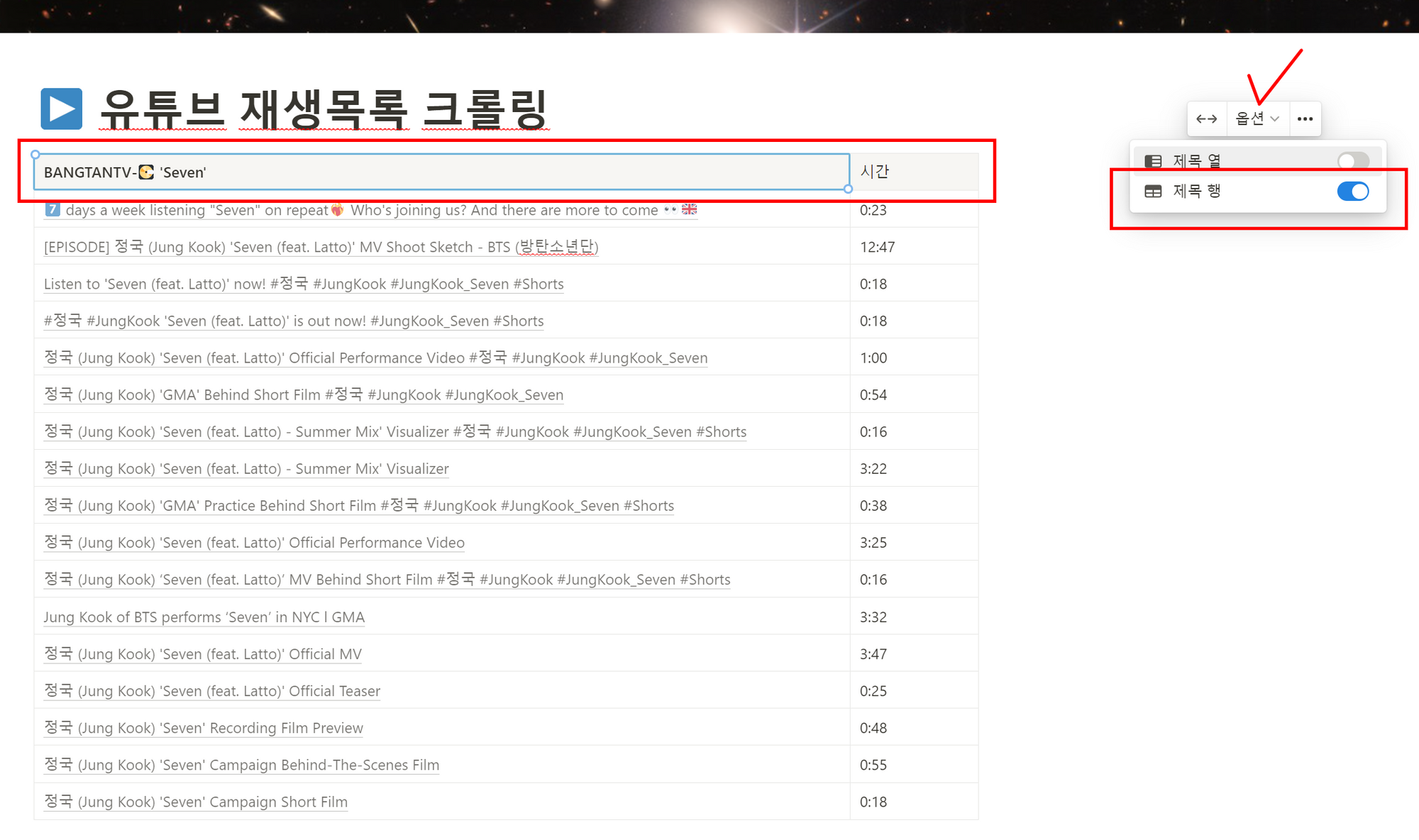
5.3 데이터베이스로 전환" 해주면 됩니다.
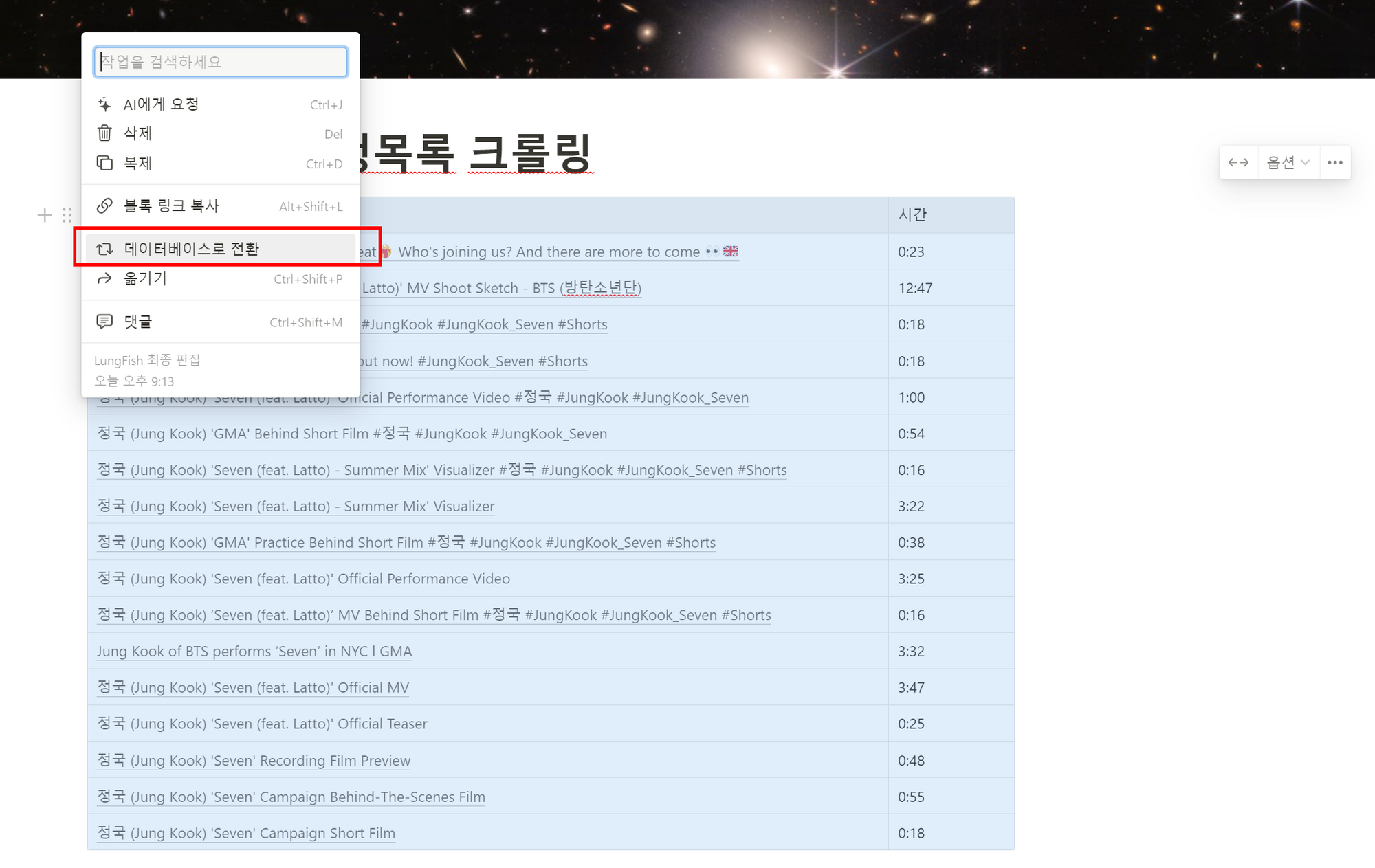
5.4 데이터 베이스 형식의 재생목록 표가 생성되었고, 페이지를 선택해서 클릭하면 해당 동영상 주소로 이동됩니다.
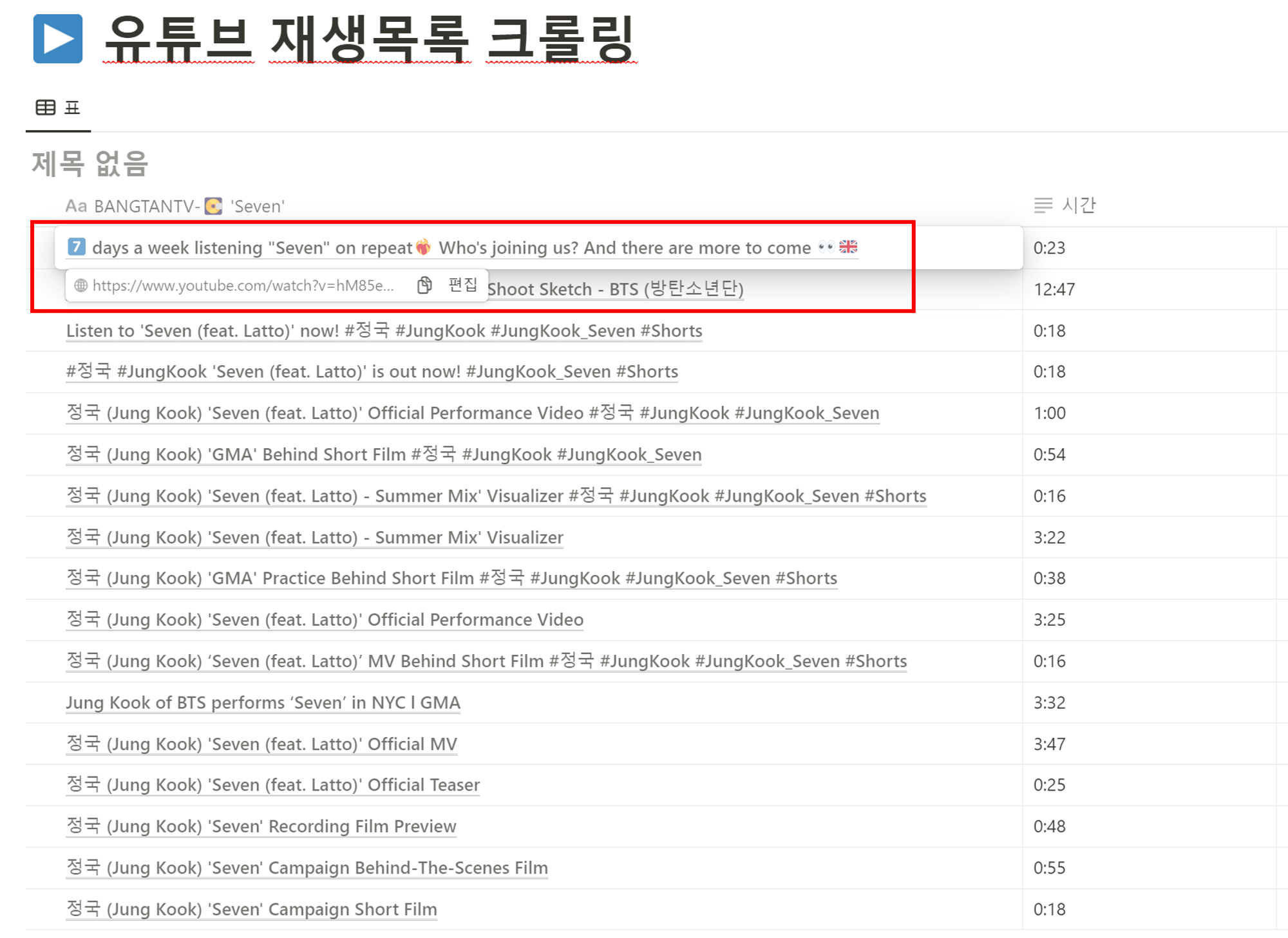

5.5 노션에 있는 표를 복사해서 티스토리에 붙여넣으면 아래와 같이 재생목록 리스트를 보기 좋게 작성할 수 있습니다. 음악 재생목록 뿐만아니라, 학습을 위한 유튜브 재생목록 등을 정리해놓고 체크박스를 만들어서 학습 체크용으로 사용할 수도 있습니다.
마치며...
원래는 코랩 환경을 통해서 진행하려고 했는데, 코랩은 한번 사용할 때는 편하기는 하지만 모듈을 인스톨 하는데 시간을 생각보다 많이 잡아먹고, 이런 부분들이 귀찮기도 해서 로컬환경으로 작업을 진행하였습니다.
유튜브 재생목록은 댓글이 없어서 동적 크롤링 할 필요가 없고, 셀레니움을 사용하지 않아도 되서 크롤링 치고는 편한 과제였습니다.
결과를 엑셀파일로 저장한 이유는, 데이터프레임에서도 하이퍼링크를 적용해서 볼 수는 있는데, html display를 사용해야 하기 때문에 to_clipboard가 안되서 노션이나 블로그에 붙여넣는게 안되어 엑셀 파일로 출력하게 되었습니다.
프로세스가 하나 더 생긴거라서 아쉽기는 한데, 조금 더 확인해보고 html코드로 만들어 보던지, 엑셀 파일 저장없이 데이터프레임만으로 출력과 복사를 끝낼 수 있도록 확인해봐야겠습니다.
▼ 전체 코드
Part 1. 유튜브 재생목록 스크래핑
# url 주소 입력
url = input('유튜브 재생목록 주소를 입력하세요: ')
# 웹 브라우저 작동을 위한 라이브러리
from selenium import webdriver
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from selenium.webdriver.common.keys import Keys
# 웹브라우저 작동을 기다리기 위한 라이브러리
import time
import random
# 시간 관련 라이브러리
from datetime import datetime, timedelta
from pytz import timezone
# IPython
from IPython.display import display
# 경고 무시
import warnings
warnings.filterwarnings(action='ignore')
# 데이터프레임 및 CSV 파일 저장을 위한 라이브러리
import pandas as pd
# 데이터프레임 출력
from tabulate import tabulate
# 크롬드라이버 option설정
options = webdriver.ChromeOptions()
options.add_argument('--headless') # Head-less 설정
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
def get_playlist(url):
# 브라우저 생성
driver = webdriver.Chrome('chromedriver', options=options)
# 웹사이트 열기
driver.get(url)
# 로딩이 끝날 때까지 2초 정도 기다림
driver.implicitly_wait(2)
# 안정적인 페이지 소스 추출을 위해 3초 정도 기다림
time.sleep(3)
# 페이지 소스 추출
global html_source, soup_source
html_source = driver.page_source
soup_source = BeautifulSoup(html_source, 'lxml')
# 파싱정보 가져오기
parsing = soup_source.find_all('a', class_ = 'yt-simple-endpoint style-scope ytd-playlist-video-renderer')
video_time = soup_source.find_all('span', class_ ='style-scope ytd-thumbnail-overlay-time-status-renderer') #검색했을 때 검색숫자가 안맞아서 확인이 필요함
global name_list, url_list, time_list
# 파싱정보 정리하기
name_list = []
url_list = []
time_list = []
for i in range(len(parsing)):
name_list.append(parsing[i].text.strip())
main = 'https://www.youtube.com'
sub = parsing[i].get('href')
url_list.append(f'{main}{sub}')
time_list.append(video_time[i].text.strip())
# 출력용 데이터 프레임 구성하기
playlist = {
'제목' : name_list,
'시간' : time_list,
'URL' : url_list,
}
# 제목에서 제거할 문자 변환하기
playlist = pd.DataFrame(playlist)
return playlist
final_result = get_playlist(url)
final_result.index = final_result.index + 1
final_result
Part 2. openpyxl로 재생목록 리스트 추출하기
from openpyxl import Workbook
from openpyxl.styles import Border, Side
from openpyxl.utils import get_column_letter
from openpyxl.styles import Font
# URL and corresponding name lists
# Create a new workbook and worksheet
wb = Workbook()
ws = wb.active
# 테두리 스타일 지정
thin_border = Border(left=Side(style='thin'),
right=Side(style='thin'),
top=Side(style='thin'),
bottom=Side(style='thin'))
list_title = soup_source.find(class_ = 'style-scope yt-dynamic-sizing-formatted-string yt-sans-28').text
channel_name = soup_source.find('a', class_ = 'yt-simple-endpoint style-scope yt-formatted-string').text
title = channel_name + "-" + list_title
name_header_cell = ws.cell(row=1, column=1, value=title) # Insert name header into cell
name_header_cell.border = thin_border
name_header_cell.font = Font(bold=True)
time_header_cell = ws.cell(row=1, column=2, value="시간") # Insert URL header into cell
time_header_cell.border = thin_border
time_header_cell.font = Font(bold=True)
# Iterate through the URL and name lists, adding each URL to a new row
for url, name, time in zip(url_list, name_list, time_list):
row = ws.max_row + 1 # Next row number
name_cell = ws.cell(row=row, column=1, value=name) # Insert name into cell
name_cell.hyperlink = url # Add hyperlink to cell
name_cell.style = "Hyperlink" # Set cell style to "Hyperlink"
name_cell.border = thin_border # Add border to cell
time_cell = ws.cell(row=row, column=2, value=time) # Insert URL into cell
time_cell.border = thin_border # Add border to cell
# 셀의 너비를 셀의 내용에 맞게 자동 조정
for column in ws.columns:
max_length = 0
column = get_column_letter(column[0].column) # Get the column name
for cell in ws[column]: # Iterate through all cells in the column
try: # Check if the cell contains text
if len(str(cell.value)) > max_length:
max_length = len(cell.value)
except:
pass
adjusted_width = (max_length + 10)
ws.column_dimensions[column].width = adjusted_width
# Save changes and create Excel file
file_name = input("저장할 파일 이름을 입력하세요: ")
wb.save(f'{file_name}.xlsx')
'웹 크롤링' 카테고리의 다른 글
| [웹크롤링] 한글 URL 인코딩/디코딩 (URL Encoding/Decoding) (0) | 2023.02.15 |
|---|
