
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 프로그래머스
- HackerRank
- 파이썬
- 텐서플로우
- Revising the Select Query II
- Tableau
- pyinstaller
- sorted()
- leetcode
- KNIME
- 물만날물고기
- KNIME 데이터 분석
- 데이터분석솔루션
- colab
- 물 만날 물고기
- 판다스
- 코랩
- python
- 데이터프레임
- SQL
- DB
- 코딩테스트
- 리스트
- 나임
- MYSQL
- pandas
- sklearn
- 해커랭크
- TensorFlow
- 태블로
- Today
- Total
물 만날 물고기
[KNIME] Workflow - 불균형 데이터 (Imbalanced data) 오버샘플링 하기 본문
🔍 예상 검색어
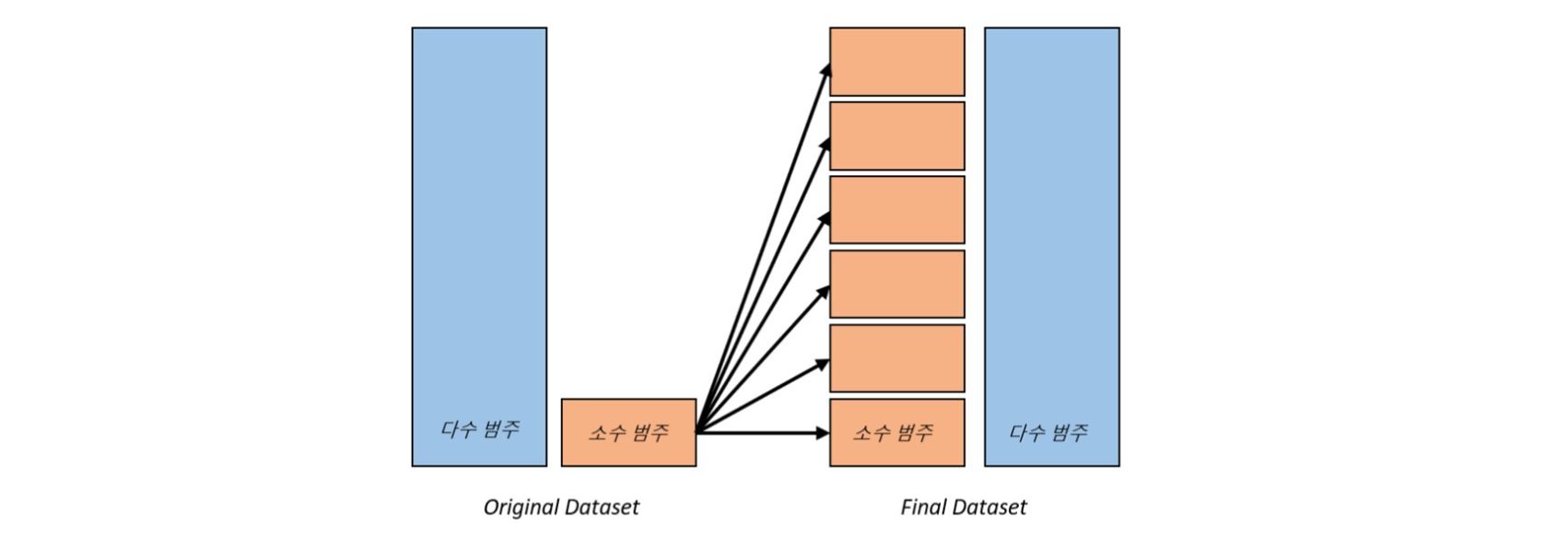
# 불균형 데이터 (Imbalanced data)
# KNIME
# Workflow
# SMOTE
# KNIME 오버샘플링
# KNIME 불균형 데이터
# KNIME SMOTE
해당 포스팅은 데이터 분석 솔루션 KNIME을 이용하여 클래스 불균형 (Imbalanced dataset)에 대한 SMOTE 오버샘플링 방법을 적용하는 방법(Workflow)을 정리하고자 하였습니다.
▼ 오버샘플링 미적용 - KNIME Workflow

▼ 오버샘플링 적용 - KNIME Workflow

1. 데이터 불러오기 ~ 2. 데이터 전처리
UCI - Breast Cancer Dataset을 불러오기 합니다. 해당 데이터셋은 URL 링크를 통해 불러오기 하였으며, 데이터 불러오기 및 전처리 관련 설명은 이전에 작성해 놓은 포스팅을 참고하시기 바랍니다.
[KNIME] Workflow - 의사결정나무(Decision Tree)를 이용한 UCI 유방암(Breast Cancer) 데이터 분석
[KNIME] Workflow - 의사결정나무(Decision Tree)를 이용한 UCI 유방암(Breast Cancer) 데이터 분석
🔍 예상 검색어 더보기 # KNIME 의사결정나무를 이용한 데이터 분석 # KNIME Decision Tree를 이용한 데이터 분석 # KNIME 유방암 데이터 분석 # KNIME Breast Cancer Data 분석 # CSV Reader # Row Filter # String To Number #
lungfish.tistory.com
3. 오버샘플링
오버샘플링은 불균형한 데이터셋에서 소수 클래스(적은 수의 샘플을 가진 클래스)의 데이터를 증가시키는 기법으로 머신러닝 모델은 데이터셋의 클래스들 사이에 균형을 가정하고 학습하기 때문에, 소수 클래스의 샘플이 부족하면 모델은 소수 클래스를 잘 학습하지 못할 수 있으며, 이로 인해 예측 성능이 저하될 수 있습니다.
오버샘플링은 소수 클래스의 샘플을 반복해서 복제하거나, 기존 샘플들을 기반으로 새로운 가상의 샘플을 생성하는 방식으로 이루어지며, 생성된 샘플은 소수 클래스의 특성을 잘 반영하도록 조절해야 해야 합니다.
오버샘플링은 데이터셋의 클래스 불균형 문제를 해결하는 데 도움을 주는 방법 중 하나이지만, 적절한 오버샘플링 기법과 파라미터 설정을 고려하여 사용이 필요합니다.
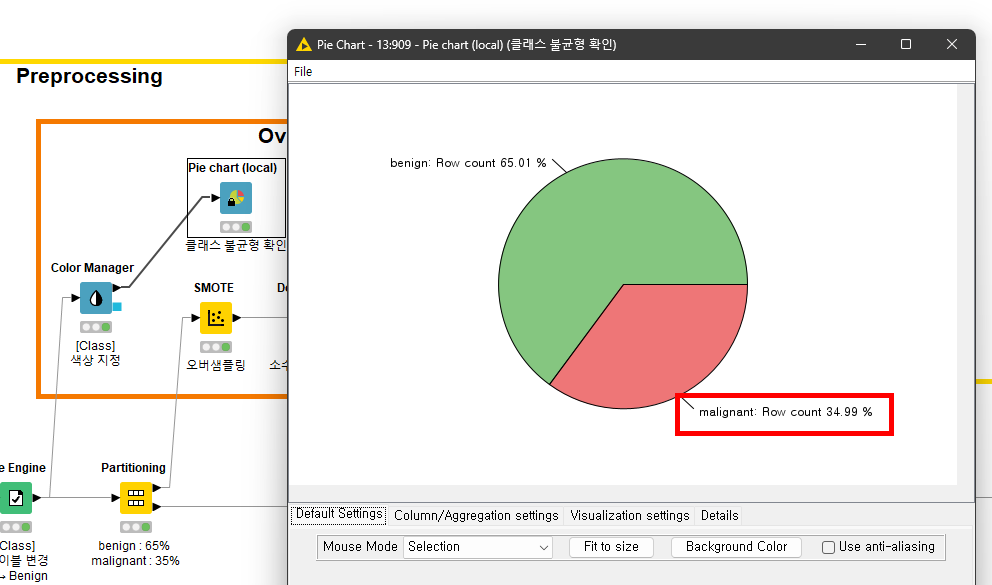
3.1 <Color Manager> 노드와 <Pie Chart (local)> 노드를 이용하여 Raw데이터의 클래스 불균형 여부를 확인합니다. 오버샘플리을 적용하기 전 benign 클래스와 maligant 클래스는 65% 대 35%로 benign (음성) 클래스의 비율이 더 높게 나오는 것을 확인할 수 있습니다.
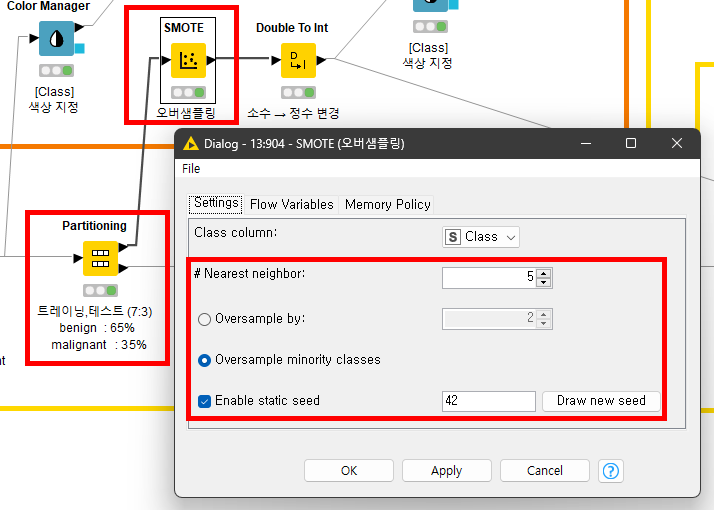
3.2 <Partioning> 노드를 이용해서 트레이닝, 테스트 데이터를 분리합니다. 그 중 트레이닝 데이터에 <SMOTE> 노드를 연결합니다. <SMOTE> 노드를 통해 Neareast neighbor 를 설정하고, 소수 데이터에 대한 오버샘플링 체크, 랜덤시드는 필요시 입력하면 됩니다.
+ 추가 설명을 덧붙이자면 오버샘플링은 여러 종류 방법들이 있는데, 그 중 SMOTE 방법은 소수 클래스의 샘플들 사이에 보간을 통해 합성 샘플을 생성하는 오버샘플링 기법으로 소수 클래스의 샘플을 선택하고 그와 가장 가까운 이웃들을 찾아 샘플들 사이의 선분 위에 합성 샘플을 생성합니다. SMOTE는 불균형 데이터셋을 균형있게 만들어주며, 분류 모델의 일반화와 성능을 향상시킬 수 있다는 장점이 있습니다.
3.3 <SMOTE> 노드를 이용하여, 오버샘플링을 진행하면 다음과 같이 기존 데이터셋에 추가된 합성데이터셋이 생기는데 거리를 기반으로 합성이 되다 보니 기존 데이터처럼 정수로 결과가 출력되는 것이 아니라 실수로 결과가 출력되는 모습을 확인할 수 있습니다.
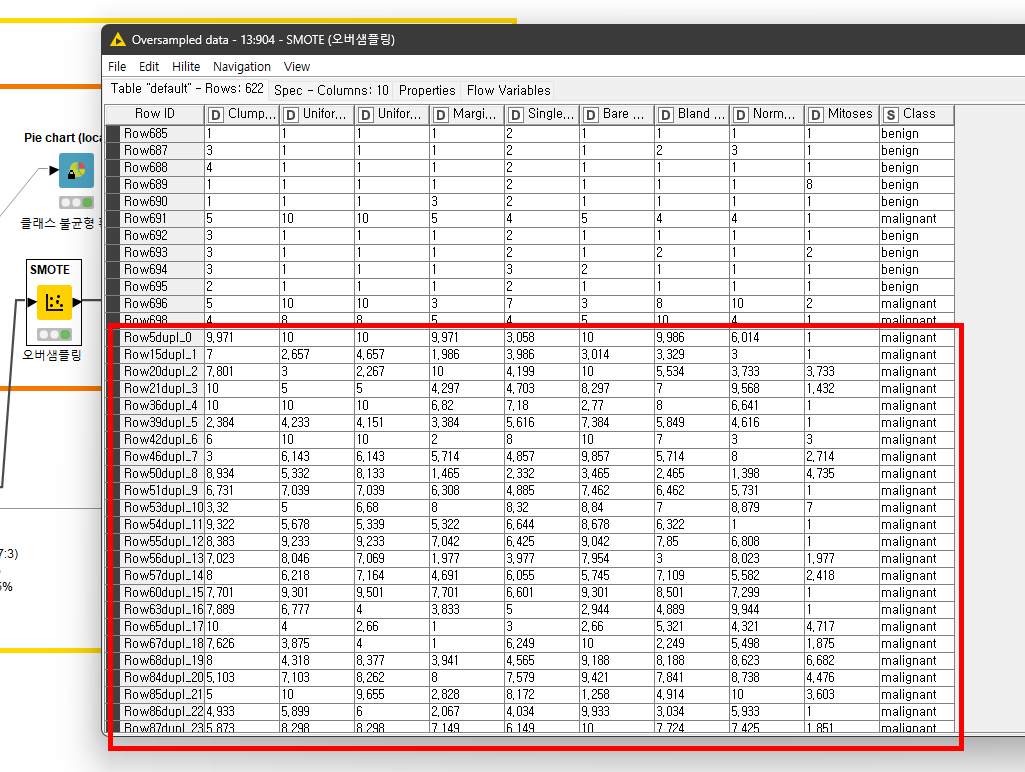
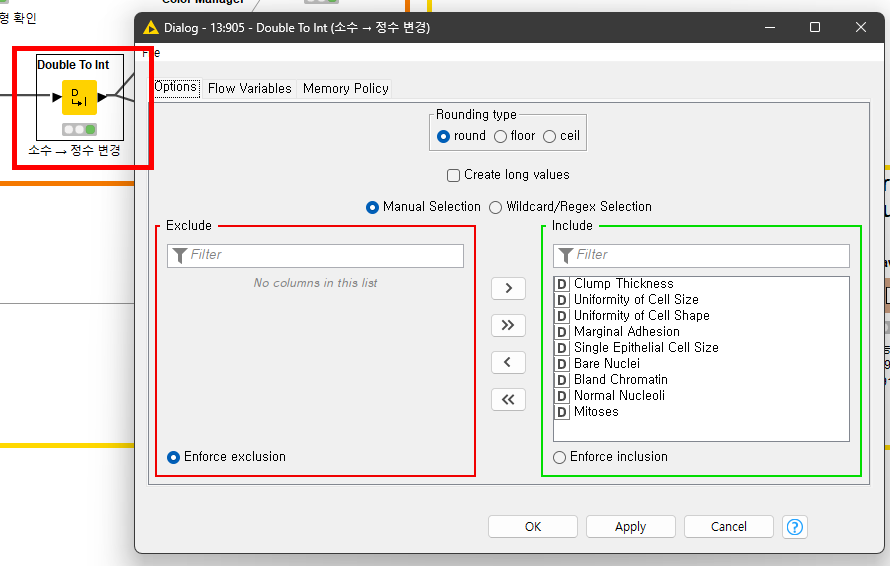
3.4 위 문제를 해결 하기 위해 <Double To Int> 노드를 이용하여 실수를 정수로 변환해 주는 작업을 진행합니다.
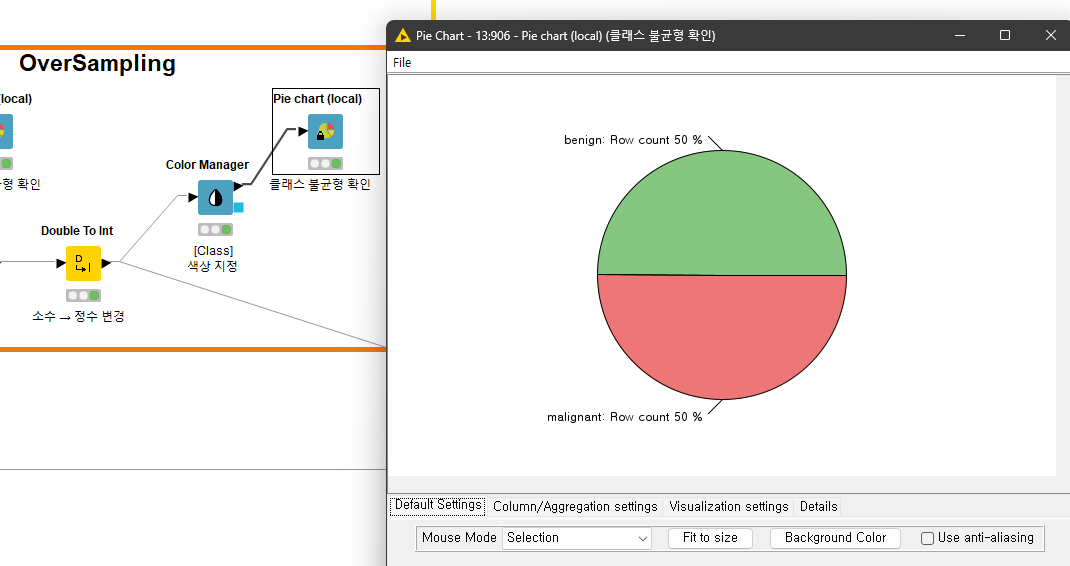
3.5 <SMOTE>노드를 통해 오버샘플링 적용 후 클래스 불균형 여부를 확인한 결과 benign 데이터와 malignant 데이터 모두 50% 대 50%로 동일하게 맞추어진 것을 확인할 수 있습니다.
4. 모델링 및 결과 확인
<Decision Tree Learner> 노드와 <Decision Tree Predictor> 노드를 통한 모델링은 앞서 설명해놓은 포스팅을 참고하시기 바라며, 오버샘플링 적용 전과 적용 후 Acc와 F1-Score에서 유의미한 변화가 있음을 확인하였습니다.
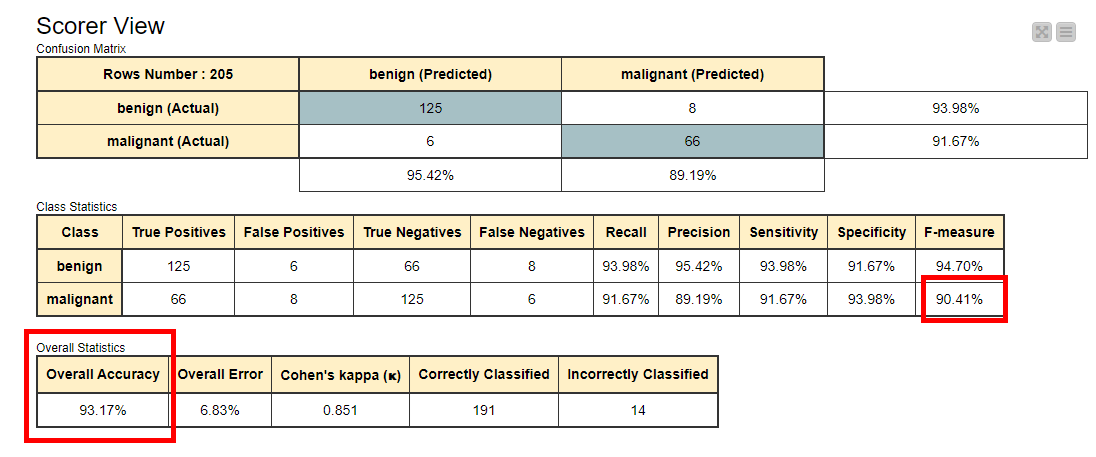
4.1 오버샘플링 적용 전 (Acc : 93.17%, F1-Score : 90.41%)
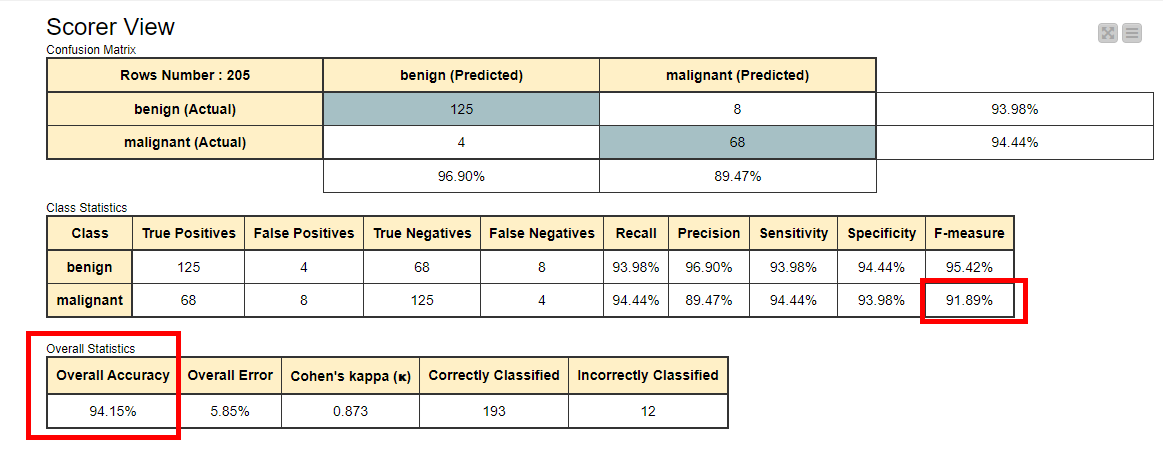
4.2 오버샘플링 적용 후 (Acc : 94.15%, F1-Score : 91.89%)
그 동안 학위 논문 작성과 코딩 테스트 준비 때문에 SQL 연습 문제에 관련한 포스팅만 올리다가, 오랜만에 KNIME 관련 포스팅을 업로드 했습니다. 앞으로 틈틈히 자주자주 더 올리려고 합니다.
저는 클래스 불균형 문제를 학위 논문 연구주제로 다루었는데, 오버샘플링이란 대중적으로 많이 사용되는 방법이 반드시 좋은 결과를 가지고 오는 것은 아닙니다. 오히려 오버샘플링 방법을 잘 못 선택할 경우 모델의 성능을 감소 시킬 수 도 있어서 실험과 평가를 통해 데이터셋에 적절한 문제를 찾아야 합니다.
그런 부분에서 KNIME은 오버샘플링 노드 종류가 매우 제한적인 것이 아쉽습니다. 물론 Python 소스코드를 통해 극복은 가능하지만 KNIME에도 다양한 오버샘플링 노드들이 생겼으면 좋겠습니다.
▼ 참고자료
'KNIME' 카테고리의 다른 글
| [KNIME] Column Expressions 노드 예시 (0) | 2023.11.06 |
|---|---|
| [KNIME] Workflow - 데이터셋에 특정 문자열로 컬럼을 추가하고 싶을 때 - 2편 (Constant Value Column 노드) (0) | 2023.02.10 |
| [KNIME] Node - "Nuemeric Binner" 연속형 변수를 범주화 하고 싶을 때 (구간화 Binning) (0) | 2023.02.07 |
| [KNIME] Workflow - Missing Value(결측치) 확인 및 처리하기 (0) | 2023.01.28 |
| [KNIME] Workflow - 각 행(인덱스)별 합계 컬럼 추가하기 (0) | 2023.01.23 |



